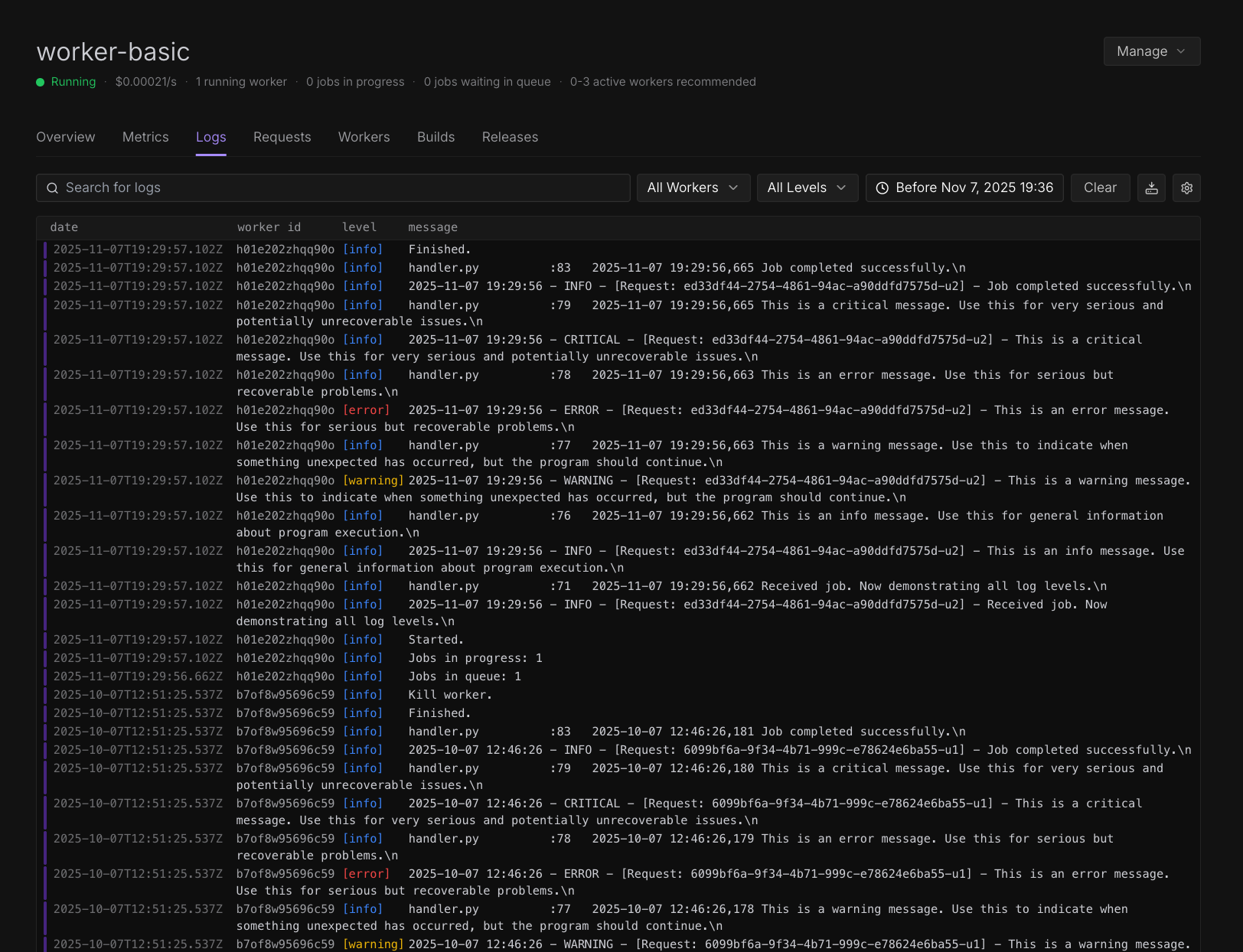
Endpoint logs
Endpoint logs are retained for 90 days, after which they are automatically removed from the system. If you need to retain logs indefinitely, you can write them to a network volume or an external service.
- Standard output (stdout) from your handler functions.
- Standard error (stderr) from your applications.
- System messages related to worker lifecycle events.
- Framework logs from the Runpod SDK. To learn more about the Runpod logging library, see the Runpod SDK documentation.
- Navigate to your Serverless endpoint in the Runpod console.
- Click on the Logs tab.
- View real-time and historical logs.
- Use the search and filtering capabilities to find specific log entries.
- Download logs as text files for offline analysis.
Worker logs
Worker logs are temporary logs that exist only on the specific server where the worker is running. These logs are not throttled, but are not persistent, and are removed when a worker terminates. To view worker logs:- Navigate to your Serverless endpoint in the Runpod console.
- Click on the Workers tab.
- Click on a worker to view its logs and request history.
- Use the search and filtering capabilities to find specific log entries.
- Download logs as text files for offline analysis.
Stream output to clients
To send progress updates or stream results to clients during job execution, see Progress updates and Streaming handlers.Troubleshooting
Missing logs
If logs are not appearing in the Logs tab:- Check log throttling: Excessive logging may trigger throttling.
- Verify output streams: Ensure you’re writing to stdout/stderr.
- Check worker status: Logs only appear for successfully initialized workers.
- Review retention period: Logs older than 90 days are automatically removed.
Log throttling
To avoid log throttling, follow these best practices:- Reduce log verbosity in production environments.
- Use structured logging to make logs more efficient.
- Implement log sampling for high-frequency events.
- Store detailed logs in network volumes instead of console output.